در عصر فناوری امروزی، هوش مصنوعی و یادگیری ماشین به بخش جدایی ناپذیر از صنایع و بخشهای مختلف تبدیل شدهاند. این تکنولوژیها بهدلیل اینکه دید و شناختهایی را در مورد روند رفتار مشتری و الگوهای عملیاتی تجاری به سازمانها ارائه میدهند، اهمیت بسیار زیادی دارند.
علاوه بر این هوش مصنوعی و یادگیری ماشین در ایجاد محصولات جدید بسیار تاثیرگذار هستند. امروزه فعالیت بزرگترین سازمانها مانند فیسبوک، گوگل، اوبر و … بر عملیات یادگیری ماشین تمرکز دارند و برای بسیاری از کسبوکارها در سرتاسر جهان، این امر به یک تمایز رقابتی حیاتی تبدیل شده است.
بنابراین انتخاب سرورهای مناسب برای هوش مصنوعی یادگیری ماشین و یادگیری عمیق بیش از گذشته اهمیت یافته است. اما قبل از اینکه بخواهیم یک اطلاعات جامع در زمینهی خرید سرور هوش مصنوعی یا غیره را در اختیارتان بگذاریم، بیایید بررسی کنیم که هوش مصنوعی، یادگیری عمیق و ماشین چیست؟
⏲ مدت زمان تخمینی مطالعه: 23 دقیقه

فهرست موضوعات
تعریف هوش مصنوعی
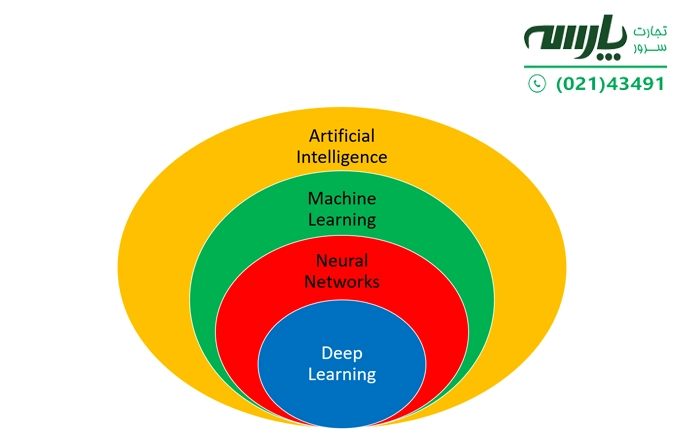
هوش مصنوعی (artificial intelligence) که به اختصار AI شناخته میشود به معنای شبیهسازی فرآیندهای هوش انسانی توسط ماشینها بهویژه سیستمهای کامپیوتری است. از کاربردهای خاص هوش مصنوعی میتوان به سیستمهای خبره، پردازش زبان طبیعی، تشخیص گفتار و بینایی ماشین اشاره کرد.
اغلب آنچه فروشندگان بهعنوان AI از آن یاد می کنند، به سادگی یکی از اجزای هوش مصنوعی است، مانند یادگیری ماشین (machine learning).
در سادهترین تعریف هوش مصنوعی به پایهای از سختافزار و نرمافزار تخصصی اشاره دارد که برای نوشتن و آموزش الگوریتمهای یادگیری ماشین مورد استفاده قرار میگیرد. هیچ زبان برنامهنویسی مترادف با هوش مصنوعی نیست، اما تعداد کمی از جمله پایتون، R و جاوا در این زمینه محبوب هستند.
عملکرد سیستمهای هوش مصنوعی بهطورکلی، بدین صورت است که سیستمها با دریافت مقادیر زیادی از دادههای آموزشی برچسبگذاریشده، دادهها را تجزیه و تحلیل میکنند تا از این الگوهای همگرا برای پیشبینی وضعیت آینده استفاده کنند. به این ترتیب، یک ربات سخنگو (chatbot) که از نمونههایی چتهای متنی تغذیه میشود، میتواند یاد بگیرد که تبادلات واقعی با افراد ایجاد کند، یا با ابزار تشخیص تصویر میتواند میلیونها تصویر را شناسایی و توصیف کند.
برنامهنویسی هوش مصنوعی بر سه مهارت شناختی تمرکز دارد:
- یادگیری
- استدلال
- خود نظارتی
فرآیندهای یادگیری این جنبه از برنامهنویسی هوش مصنوعی در به دست آوردن دادهها و ایجاد قوانینی برای چگونگی تبدیل دادهها به اطلاعات عملی متمرکز است. قوانین، که الگوریتم نامیده میشوند، دستورالعملهای گام به گام را برای دستگاههای محاسباتی بهمنظور تکمیل یک کار خاص ارائه میدهند.
خرید سرور hp
تعریف یادگیری ماشین
زیرمجموعهای از هوش مصنوعی (AI) و علوم کامپیوتر، یادگیری ماشین (machine learning) با اختصار ML است. در واقع یادگیری ماشین نوعی هوش مصنوعی (AI) است که به برنامههای نرمافزاری اجازه میدهد تا پیشبینی دقیقتری در نتایج داشته باشند، بدون اینکه به صراحت برای این کار برنامهریزی شده باشند. همچنین الگوریتمهای یادگیری ماشین از دادههای تاریخی به عنوان ورودی برای پیشبینی مقادیر خروجی جدید استفاده می کنند.
موتورهای توصیه (Recommendation engines) یک مورد رایج در یادگیری ماشین هستند. سایر کاربردهای محبوب این تکنولوژی عبارتند از:
- تشخیص تقلب
- فیلتر هرزنامه
- شناسایی تهدیدهای بدافزاری
- اتوماسیون فرآیند کسب و کار (BPA)
- نگهداری دادههای پیشبینی شده
در یادگیری ماشین با مطالعه و استفاده از دادهها و الگوریتمها نحوهی یادگیری انسان تقلید میشود. این فرآیند به ماشینها کمک میکند تا به تدریج دقت خود را بهبود ببخشند.
یادگیری ماشینی اغلب بر اساس نحوهی یادگیری الگوریتم در پیشبینی دقیقتر طبقهبندی میشود که شامل چهار رویکرد اساسی است:
- یادگیری با نظارت
- یادگیری بدون نظارت
- یادگیری نیمه نظارتی
- یادگیری تقویتی
نوع الگوریتمی که دانشمندان دادههای الگوریتمی برای استفاده انتخاب میکنند بستگی به نوع دادههایی دارد که میخواهند آن را پیشبینی کنند.
پشتیبانی سرور hp
تعریف یادگیری عمیق
یادگیری عمیق به انگلیسی Deep learning که با اختصار DL مشخص میشود به معنای رایجترین پیادهسازی یک شبکه عصبی برای انجام بسیاری از وظایف هوش مصنوعی است. دانشمندان داده از چارچوبهای نرمافزاری مانند TensorFlow و PyTorch برای توسعه و اجرای الگوریتمهای DL استفاده میکنند.
یادگیری عمیق در اصل نوعی یادگیری ماشین با شبکه عصبی چند لایه است که یادگیری ماشین برای ترکیب دادهها به شکل پیشبینی عمل میکند. دو کاربرد یادگیری عمیق عبارتند از:
- همگرایی (regression) یا پیشبینی نتیجه
- طبقهبندی یا (classification) متمایز کردن بین گزینههای گسسته
در هر مورد دادههای آموزشی وجود دارد که برای تنظیم وزنها (پارامترهای ناشناخته) استفاده میشود که یک تابع ضرر (تابع هدف) را به حداقل میرساند. همچنین یک مدل آموزش دیده، نتایج را براساس شرایط ورودی جدید که در مجموعه دادههای اصلی نیستند، پیشبینی میکند.
برخی از مراحل معمول برای ساخت و استقرار یک برنامه یادگیری عمیق عبارتند از: تلفیق دادهها، پاکسازی دادهها، ساخت مدل، آموزش، اعتبارسنجی و استقرار است که برای هر یک از مراحل نمونه کد پایتون ارائه شده است.
یک راه محبوب برای شروع یادگیری عمیق، اجرای این چارچوبها در فضای ابری است. با این حال، وقتی شرکتها و سازمانها شروع به رشد و بلوغ مهارتهای خود در زمینهی هوش مصنوعی میکنند، بهدنبال راههایی برای اجرای این چارچوبها در مراکز داده خودشان هستند تا از هزینهها و سایر چالشهای هوش مصنوعی مبتنی بر ابر اجتناب کنند.
آموزش یادگیری عمیق اغلب بهعنوان کانال ارتباط پردازش داده، طراحی میشود. یعنی ابتدا دادههای ورودی خام باید از نظر قالب، اندازه و سایر عوامل مربوط به داده تهیه شوند.
همچنین دادهها اغلب پیش پردازش میشوند تا ورودی یکسان با روشهای مختلف به مدل ارائه شود. سپس با توجه به آنچه دانشمندان داده تعیین کردهاند، مجموعهی آموزشی قویتری ارائه میشود. بهعنوان مثال، تصاویر را میتوان با مقدار تصادفی چرخاند، بهطوری که مدل یاد میگیرد اشیاء را بدون توجه به جهت آن تشخیص دهد. سپس دادههای آماده شده به الگوریتم DL وارد میشوند.
شکل 1 نمودار فلشی با برچسب «جمعآوری دادهها و برچسبگذاری» را نشان میدهد که از یک دوربین امنیتی به مجموعهای از سه شکل در حال راه رفتن، اشاره میکند. فلشی با برچسب «آمادهسازی دادهها Data Preparation» از این تصاویر به یک تصویر منفرد در حال راه رفتن اشاره میکند. همچنین فلشی دیگر با عنوان «پیشپردازش preprocessing » از این تصویر واحد به مجموعهای از سه تصویر از شکل در حال راه رفتن در جهتهای مختلف اشاره میکند. همچنین فلشی دیگر با برچسب «آموزش Training» از این تصاویر به نمایش نمادین یک شبکه عصبی اشاره میکند.
تفاوت ویندوز سرور با ویندوز معمولی
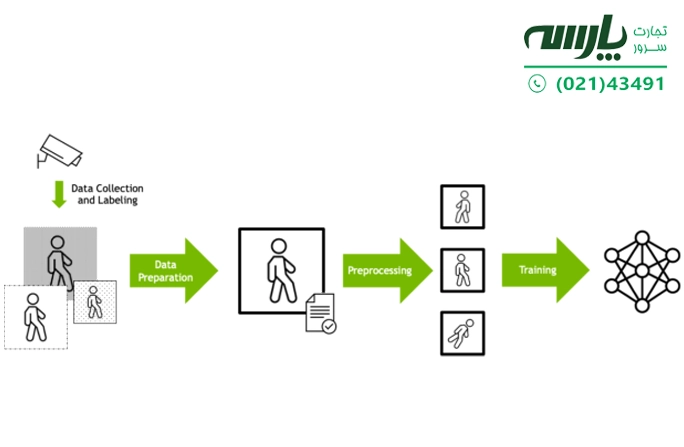
شکل 1. کانال ارتباط داده آموزش یادگیری عمیق
سرور پردازش موازی چیست؟
پردازش موازی (Parallel processing) روشی در محاسبه اجرای دو یا چند پردازنده (CPU) برای رسیدگی به بخشهای جداگانه یک عملکرد کلی است. جدا کردن بخشهای مختلف یک کار در میان چندین پردازنده به کاهش زمان اجرای یک برنامه کمک میکند. هر سیستمی که بیش از یک CPU دارد، میتواند پردازش موازی و همچنین پردازندههای چند هستهای را که امروزه در سرورها یافت میشوند، را انجام دهد.
سرورهای پردازش موازی، بیشتر برای انجام وظایف و محاسبات پیچیده استفاده میشود. همچنین دانشمندان داده از سرور پردازش موازی، برای کارهای محاسباتی و دادههای فشرده استفاده میکنند.
در یک سرور پردازش موازی، کاربر یک عملکرد پیچیده را با یک ابزار نرمافزاری به چند قسمت تقسیم میکند که هر قسمت به یک پردازنده اختصاص داده میشود. سپس هر پردازنده قسمت مرتبط با خود را حل میکند. پس از پایان کار دادهها توسط یک ابزار نرمافزاری برای خواندن راه حل دوباره گردآوری میشوند.
سرور دی ال 380

در این سرور پردازندهها برای برقراری ارتباط با یکدیگر به نرمافزار متکی هستند تا بتوانند تغییرات را در مقادیر داده شده، و بهصورت موازی طبق دستور انجام دهند. با فرض اینکه همه پردازندهها با یکدیگر همگام باشند، در پایان کار، نرمافزار تمام قطعات داده را در کنار هم قرار میدهد.
سرورها بدون چندین پردازنده نیز میتوانند در پردازش موازی استفاده شوند، البته اگر با همدیگر شبکه شده و یک خوشه را تشکیل دهند.
انواع مختلفی از پردازش موازی وجود دارد که دو نوع از رایجترین آنها عبارتند از SIMD و MIMD.
SIMD یا دادههای چندگانه تک دستورالعمل (single instruction multiple data)، شکلی از پردازش موازی است که در آن یک سرور دارای دو یا چند پردازنده از مجموعه دستورالعملهای یکسان است در حالی که هر پردازنده دادههای متفاوتی را مدیریت میکند اما SIMD بیشتر برای تجزیه و تحلیل مجموعه دادههای بزرگی که براساس معیارهای مشخص شده یکسان هستند، استفاده میشود.

سرور های قدرتمند برای یادگیری عمیق و هوش مصنوعی AI
با بررسی هوش مصنوعی و یادگیری ماشین و درک از نحوهی آموزش DL زمان آن است که براساس نیازهای محاسباتی خاص بتوانید سروری قدرتمند برای یادگیری عمیق و هوش مصنوعی پیکربندی کنید. پیکربندی سرور و ساخت ایستگاه کاری در زمینه ی یادگیری ماشین و هوش مصنوعی اگرچه میتواند دشوار باشد اما انتخاب درست تعدادی قطعات سختافزاری براساس انواع پروژههایی که قصد اجرای آن را دارید، میتواند این روند را آسان سازد.
آموزش کانفیگ سرور
پردازنده گرافیکی (GPU)
در قلب سرور یادگیری عمیق، پردازنده گرافیکی قرار دارد تا بتواند فرآیند محاسبه مقادیر مختلف را برای هر لایه از یک شبکه و در نهایت مجموعه عظیمی از ضربهای ماتریس انجام دهد. در این سرور دادههای هر لایه را میتوان به صورت موازی و با مراحل هماهنگ بین لایههای دیگر انجام داد.
پردازندههای گرافیکی برای انجام ضرب ماتریس به صورت موازی طراحی شدهاند و ثابت کردهاند که برای دستیابی به سرعتهای فوقالعاده در یادگیری عمیق بهشدت تاثیرگذار هستند. در واقع GPU ها برای آموزش DL عامل محرک اندازه، مدل و … هستند. بنابراین باید به سراغ پردازندههای گرافیکی با حافظه بزرگتر و سریعتر، مانند پردازنده گرافیکی NVIDIA A100 Tensor Core، بروید تا بتوانید با سرعت بیشتر در یادگیری دستهای از دادههای آموزشی گام بردارید.
امروزه انواع مختلفی از GPU وجود دارد که میتوانید آنها را انتخاب کنید. توصیه ما این است که همیشه سراغ بهترینها بروید تا از عملکرد سرورتان نگران نباشید. NVIDIA GeForce RTX 3090 دارای 24 گیگابایت حافظه است و نیروگاهی برای انواع پروژههای هوش مصنوعی است. با این حال، یک گزینه ارزانتر که میتواند در پروژههای مختلف همراهتان باشد، NVIDIA GeForce RTX 3060 با حافظه 12 گیگابایتی است.
یک GPU عظیم در سرور یادگیری عمیق و هوش مصنوعی بهعنوان یک قطعهی سختافزاری ضروری شناخته میشود، که ممکن است برخی از افراد بهدلیل هزینه زیاد از آن صرفنظر کنند. با اینحال توجه داشته باشید که توجه نکردن به GPU میتواند عملکرد برنامهها را تغییر دهد یا خراب کند.
آمادهسازی دادهها و محاسبات پیشپردازش مورد نیاز برای آموزش DL بیشتر روی CPU انجام میشود، اگرچه نوآوریهای اخیر این امکان را فراهم کردهاند که بیشتر بر روی GPUها انجام شود، با اینحال CPU در سرور هوش مصنوعی و یادگیری ماشین و عمیق برای حفظ کارآیی بالا و سرعت کافی نیاز است.
CPU را باید در کلاس سازمانی مانند خانواده پردازندههای Intel Xeon Scalable یا AMD EPYC انتخاب کنید. همچنین نسبت هستههای CPU به GPU باید به اندازه کافی بزرگ باشد تا کانال ارتباطی را ادامه دهد.
حافظه سیستم (System memory)
امروزه بزرگترین مدلهای سرورهای آموزش یادگیری عمیق فقط زمانی کار میکنند که مقدار بسیار زیادی داده ورودی برای آموزش وجود داشته باشد. این دادهها به صورت دستهای از ذخیرهسازی بازیابی میشوند و سپس توسط CPU در حافظه سیستم قبل از تغذیه GPU روی آن کار میکند.
برای اینکه این فرآیند با سرعت ثابتی جریان داشته باشد، حافظه سیستم باید به اندازه کافی بزرگ باشد تا سرعت پردازش CPU با سرعت پردازش دادهها توسط GPU مطابقت داشته باشد. این سرعت برحسب نسبت حافظه سیستم به حافظه GPU (در تمام GPUهای موجود در سرور) تعریف میشود. براساس مدلها و الگوریتمهای مختلف این نسبت میتواند متفاوت باشد، اما بهتر است همیشه نسبت بالاتری را انتخاب کنید تا GPU منتظر داده نماند.
آداپتور شبکه (Network adapter)
با بزرگتر شدن مدلهای یادگیری عمیق، تکنیکهایی برای انجام آموزش با چندین GPU که با هم کار میکنند نیز توسعه داده شده است. هنگامیکه بیش از یک GPU در یک سرور نصب میشود، آنها میتوانند از طریق گذرگاه PCIe با یکدیگر ارتباط برقرار کنند، اگرچه میتوان از فناوریهای تخصصیتری مانند NVLink و NVSwitch برای بالاترین عملکرد استفاده کرد.
همچنین آموزش استفاده از چندین GPU میتواند برای کار در چندین سرور نیز گسترش یابد. در این حالت، آداپتور شبکه به یک جزء حیاتی، در طراحی سرور تبدیل میشود. بنابراین استفاده از آداپتورهای اترنت یا InfiniBand با پهنای باند بالا برای به حداقل رساندن تنگناهای ناشی از انتقال داده در هنگام اجرای آموزش DL چند گره ضروری هستند.
چارچوبهای یادگیری عمیق از کتابخانههایی مانند NCCL برای انجام هماهنگی بین GPUها به شیوهای بهینه و کارآمد استفاده میکنند. در نتیجه فناوریهایی مانند GPUDirect RDMA امکان انتقال دادهها از شبکه را بهطورمستقیم به GPU و بدون نیاز به عبور از CPU فراهم میکنند، که باعث حذف تأخیر میشود.
با اینحال در حالت ایدهآل، باید یک آداپتور شبکه برای هر یک یا دو GPU در سیستم وجود داشته باشد تا اختلاف در هنگام انتقال داده به حداقل برسد.
بیشتر دادههای آموزشی DL روی آرایههای ذخیرهسازی خارجی (external storage arrays) قرار میگیرند. درایوهای NVMe روی سرور میتوانند با ارائه ابزاری برای حافظه کش دادهها، روند آموزش را تا حد زیادی سرعت ببخشند. بیشتر الگوهای یادگیری عمیق I/O از تکرارهای متعدد خواندن دادههای آموزشی تشکیل شده است. بنابراین در اولین گذر یا دوره آموزشی، دادههایی خوانده میشود که برای شروع آموزش مدل مورد استفاده قرار میگیرند. اگر حافظه نهان محلی کافی در گره (node) ارائه شود، در گذرهای بعدی، دادهها از خواندن مجددشان از ذخیرهساز راه دور جلوگیری میکنند. برای جلوگیری از تداخل هنگام خروج داده از حافظه راه دور، باید یک درایو NVMe در هر CPU وجود داشته باشد.
براساس نوع نیاز کاریتان انتخاب ذخیرهساز متفاوت است اما ایدهی استفاده از SSD یا HDD برای یادگیری ماشین بهتر است. همچنین میتوانید مانند سرورهای تیغهای هر دو را با هم داشته باشید.
داشتن یک SSD که به سرعت دادهها را در صورت نیاز منتقل میکند، بسیار راحت خواهد بود. با این حال، برای دادههایی که به طور مکرر جابهجا نمیشوند یا در نهایت در یک وضعیت ذخیرهسازی دائمی قرار میگیرند، HDD انتخاب بهتری خواهد بود بهویژه اینکه قیمت ارزانتری نیز دارد.
اگر از مجموعه دادههای بزرگ استفاده نمیکنید و در عوض برای آموزش برنامه هوش مصنوعی از شبیهسازیها استفاده میکنید، ممکن است بتوانید نیاز به یک راهحل ذخیرهسازی دائمی مانند HDD را دور بزنید تا در هزینهها صرفهجویی کنید. با اینحال بهترین و مطمئنترین ذخیرهساز که برای هوش مصنوعی و یادگیری ماشین میتواند در زمان شما صرفهجویی کند و یک سرمایهگذاری در درازمدت باشد خرید SSD است.
سرور g10 plus
توپولوژی PCIe
با تعامل پیچیده بین CPU، GPU و شبکه، داشتن یک طراحی اتصال استاندارد که از هرگونه تنگنا در کانال ارتباطی آموزش DL جلوگیری کند و باعث دستیابی به بهترین عملکرد شود، از اهمیت بالایی برخوردار است. امروزه بیشتر سرورهای سازمانی از PCIe بهعنوان وسیلهای برای ارتباط بین اجزا استفاده میکنند. ترافیک اولیه در گذرگاه PCIe در مسیرهای زیر رخ میدهد:
- از حافظه سیستم تا GPU
- بین پردازندههای گرافیکی روی همان سرورها در طول آموزش چند GPU
- بین GPU و آداپتور شبکه در طول آموزش چند گره
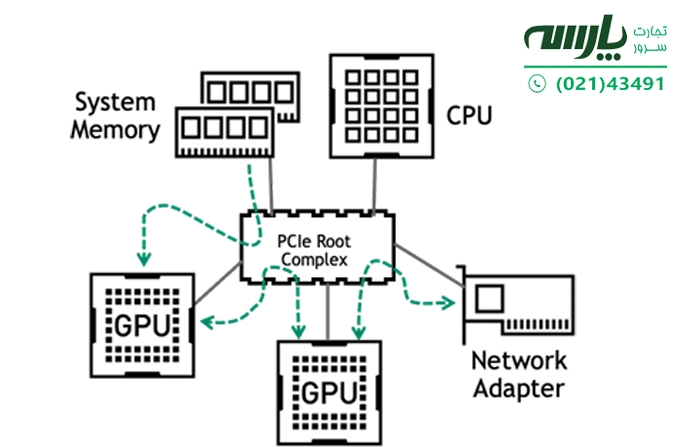
شکل 2 . مسیرهای ترافیک داده اولیه PCIe
سرورهایی که برای یادگیری عمیق استفاده میشوند باید توپولوژی PCIe متعادلی داشته باشند و GPU ها به طور مساوی در سوکتهای CPU و پورتهای ریشه PCIe پخش شوند. همچنین در همه موارد، تعداد خطوط PCIe به هر GPU، باید حداکثر تعداد پشتیبانی شده باشد.
اگر در سرور چندین GPU وجود دارد و تعداد خطوط PCIe از CPU برای جا دادن همهی آنها کافی نیست، باید یک سوئیچ PCIe تهیه کنید. در این مورد، تعداد لایههای سوئیچ PCIe باید به یک یا دو لایه محدود شوند تا تاخیر PCIe به حداقل برسد. به طور مشابه، آداپتورهای شبکه و درایوهای NVMe باید تحت همان سوئیچ PCIe یا مجتمع ریشه PCIe قرار بگیرند که پردازندههای گرافیکی هستند.
در پیکربندیهای سروری که از سوئیچهای PCIe استفاده میشود، سیستم برای بهترین عملکرد باید در زیر همان سوئیچ PCIe قرار گیرند که پردازندههای گرافیکی تعبیه شدهاند.
نرمافزار NVIDIA AI Enterprise
در کنار سختافزار مناسب، مشتریان سازمانی باید دارای یک راهحل نرمافزاری پشتیبانیشده برای بارهای کاری هوش مصنوعی و یادگیری ماشین باشند. نرمافزار NVIDIA AI Enterprise مجموعهای بهینهسازی شده و ابری از نرمافزارهای هوش مصنوعی، یادگیری ماشین، تجزیه و تحلیل داده است، تا هر سازمانی بتواند بهترین کارآیی را در این موارد داشته باشد. همچنین این نرمافزار دارای مجوز برای استقرار در هر جایی از مرکز داده سازمانی گرفته تا ابر عمومی نیز است. نرمافزار AI Enterprise شامل پشتیبانی جهانی از کسبوکارهای مختلف است تا پروژههای مبتنی بر هوش مصنوعی در مسیر خود ادامه بدهند.
وقتی NVIDIA AI Enterprise را روی سرورها با پیکربندی بهینه اجرا میکنید، میتوانید مطمئن باشید که از سرمایهگذاری سخت افزاری خود بهترین بهره را خواهید برد.
انتخاب یک سیستم معتبر برای پشتیبانی از آموزش یادگیری عمیق
پیکربندی و طراحی یک سرور بهینه شده برای آموزش یادگیری عمیق پیچیده است. مشاورین تجارت سرور پارسه براساس سالها تجربه با این بارهای کاری آشنایی دارند و میتوانند پیکربندیهای سرور از هوش مصنوعی و یادگیری ماشین گرفته تا DL را برای انواع مختلف بارهای کار انجام دهند. برای اطلاع بیشتر در این زمینه میتوانید با مشاورین ما تماس بگیرید.
مقدار رم و حافظه مورد نیاز برای یادگیری عمیق و یادگیری ماشین
یکی از موارد اساسی در سرورهای مبتنی بر هوش مصنوعی و یادگیری ماشین مقدار رم و حافظه است. درک الزامات مقدار رم و حافظه موردنیاز برای یادگیری ماشین بخش مهمی از فرآیند پیکربندی سرور است که بیشتر اوقات از سمت کاربران نادیده گرفته میشود. با اینحال برای شروع متوسط حافظه رم که نیاز دارید 16 گیگابایت است اما برخی از برنامهها به حافظه بیشتری نیاز دارند.
اگرچه یادگیری ماشین نسبت به یادگیری عمیق و هوش مصنوعی به حافظه کمتری نیاز دارد اما واقعیت این است که مقدار رم مورد نیاز برای یادگیری عمیق و ماشین بیچون و چرا به نوع پروژهای که در حال انجام آن هستید بستگی دارد. بهعنوان مثال، اگر شما در حال اجرای یک پروژه یادگیری عمیق هستید که به شدت به مقادیر انبوه دادههایی که وارد و پردازش میشوند بستگی دارد، به میزان حافظه زیادی نیاز خواهید داشت. با این حال، اگر برنامهای را به صورت بصری یا شبیهسازی آموزش میدهید، به حافظه کمتری نیاز دارید، اما حجم کاری سنگینتری خواهد داشت که باعث میشود نیاز به پردازش سریع داشته باشید. از سوی دیگر، یادگیری ماشین که کمتر به یک برنامه هوش مصنوعی مربوط میشود و بیشتر به توانایی پردازش دادهها و تولید راهحلهایی ارتباط دارد، مقدار حافظه رم میتواند جابهجا یا کم و زیاد شود.
یک قانون کلی برای RAM در یادگیری عمیق این است که اندازه حافظه GPU، رم داشته باشید و برای رشد سرور 25 درصد بیشتر از آن در نظر بگیرید. (مقدار حافظه GPU+ 25%= رم سرور یادگیری عمیق) این فرمول ساده به شما کمک میکند تا از نیازهای رم خود باخبر شوید.
همانطور که پیشتر اشاره کردیم، داشتن چندین پردازنده گرافیکی برای یک پروژه هوش مصنوعی رایج است! با این حال، زمانیکه از چندین GPU استفاده می کنید، چقدر باید نگران حافظه RAM باشید؟ خب جواب کمی شبیه به شمشیر دو لبه است. در واقع شما هرگز به حافظه رم نیاز نخواهید داشت یا حتی قادر به استفاده از رم بیشتر نخواهید بود! بهعنوان مثال، اگر از کارت گرافیک NVIDIA GeForce RTX 3090 استفاده می کنید، باید یک حافظه رم 24 گیگابایت+25 درصد داشته باشید اما اگر تصمیم به اضافه کردن بیشتر داشته باشید نمیتوانید بیشتر از 24 گیگابایت حافظه رم خود استفاده کنید. زیرا هنگامیکه کار به پایان میرسد، RAM در نهایت به حداکثر ظرفیت بر اساس GPU با بیشترین مقدار حافظه کاهش خواهد یافت.

تفاوت بین AI Servers و AI Workstations
اگر تعجب میکنید که چگونه بین یک سرور هوش مصنوعی (AI Servers) با یک ایستگاهکاری هوش مصنوعی (AI Workstations) تفاوت وجود دارد، شما تنها نیستید. اگرچه از نظر فنی میتوانید از یکی بهعنوان دیگری استفاده کنید. با این حال، نتایج خواسته شده از هر یک با توجه به حجم کاری متفاوت خواهد بود. به همین دلیل، درک واضح تفاوت بین سرورهای هوش مصنوعی و ایستگاههای کاری هوش مصنوعی مهم است.
با کنار گذاشتن هوش مصنوعی برای لحظهای، سرورها به طور کلی تمایل به شبکه دارند و بهعنوان یک منبع مشترک در دسترس هستند تا خدمات قابل دسترسی در سراسر شبکه را اجرا کنند اما ایستگاههای کاری بیشتر برای اجرای درخواستهای یک کاربر خاص یا برنامه کاربردی در نظر گرفته میشوند.
حال سوال این است که « آیا یک ایستگاه کاری میتواند به عنوان یک سرور و یا یک سرور به عنوان یک ایستگاه کاری عمل کند؟» پاسخ «بله» است، اما نادیده گرفتن هدف طراحی ایستگاه کاری یا سرور هرگز منطقی نیست. بهعنوان مثال، هم ایستگاههای کاری و هم سرورها میتوانند بارهای کاری چند رشتهای را پشتیبانی کنند، اما اگر یک سرور بتواند 20 برابر بیشتر از یک ایستگاه کاری رشته ها را پشتیبانی کند (همهی چیزهای دیگر برابر هستند)، سرور برای برنامههایی که رشتههای زیادی را برای پردازشگر ایجاد میکنند، مناسبتر خواهد بود.
سرورها به گونهای بهینه شدهاند که مشتریان آنها را بهعنوان یک منبع شبکه در نظر بگیرند در حالی که ایستگاههای کاری بیشتر برای عملکردهای عظیم، اشتراکگذاری، موازیسازی و قابلیتهای دیگر شبکه بهینهسازی نمیشوند.

تفاوتهای خاص: سرورها و ایستگاههای کاری هوش مصنوعی
سرورها اغلب سیستمعاملی را اجرا میکنند که برای سرور طراحی شده، در حالی که سیستمعاملهای ایستگاههای کاری مخصوص این سیستم است. بهعنوان مثال، مایکروسافت ویندوز 10 برای استفاده شخصی و دسکتاپ مناسب است در حالی که مایکروسافت ویندوز سرور بر روی سرورهای اختصاصی و برای خدمات شبکه مشترک اجرا میشود. این اصل در سرورها و ایستگاههای کاری هوش مصنوعی نیز یکسان است.
بیشتر ایستگاههای کاری هوش مصنوعی که برای یادگیری ماشین، یادگیری عمیق و توسعه هوش مصنوعی استفاده میشوند، مبتنی بر لینوکس هستند. همین امر در مورد سرورهای هوش مصنوعی نیز صادق است.
از آنجایی که استفاده مورد نظر از ایستگاههای کاری و سرورها متفاوت است، سرورها را میتوان به خوشههای پردازنده، منبع حافظه CPU و GPU بزرگتر، هستههای پردازشی بیشتر و قابلیتهای چند رشتهای و شبکه بیشتر مجهز کرد. البته توجه داشته باشید که به دلیل تقاضاهای شدیدی که برای سرورها به عنوان یک منبع مشترک است، بهطورکلی تقاضای بیشتری نیز برای ظرفیت ذخیرهسازی، عملکرد ذخیرهسازی فلش و زیرساخت شبکه وجود دارد.
GPU: یک عنصر ضروری
امروزه GPU تبدیل به یک عنصر ضروری در ایستگاههای کاری هوش مصنوعی مدرن و سرورهای AI شده است. برخلاف پردازندههای مرکزی، پردازندههای گرافیکی توانایی افزایش توان عملیاتی دادهها و تعداد محاسبات همزمان در یک برنامه را دارند.
اگرچه در ابتدا پردازندههای گرافیکی برای تسریع رندر گرافیکی طراحی شدند اما از آنجایی که پردازندههای گرافیکی میتوانند بهطور همزمان بسیاری از دادهها را پردازش کنند، کاربردهای مدرن جدیدی در یادگیری ماشین، ویرایش ویدیو، رانندگی مستقل و… برعهده گرفتهاند.
اگرچه بارهای کاری هوش مصنوعی را میتوان روی CPUها اجرا کرد اما زمان رسیدن به نتیجه با یک GPU ممکن است 10 تا 100 برابر سریعتر باشد. برای مثال، پیچیدگی یادگیری عمیق در پردازش زبان طبیعی، موتورهای توصیهگر و طبقهبندی تصویر، از شتاب GPU سود بیشتری میبرند.
همچنین عملکرد برای آموزش اولیه یادگیری ماشین و مدلهای یادگیری عمیق نیز مورد نیاز است. زمانیکه پاسخ بلادرنگ (مانند مکالمه در هوش مصنوعی) در حالت بهرهوری اجرا میشود، عملکرد نیز ناخواسته بالاتر میرود.
استفاده سازمانی (Enterprise)
در استفاده سازمانی این نکته مهم است که سرورها و ایستگاههای کاری مبتنی بر هوش مصنوعی بهطور یکپارچه در یک سازمان و با ابر کار کنند و هر کدام جایگاهی را در یک سازمان تنظیم کنند.
بهترین میل سرور سازمانی
سرورهای هوش مصنوعی (AI servers)
در سرورهای هوش مصنوعی بهویژه مدلهای بزرگ بهطور مؤثرتری آموزش بر GPU و خوشههای سرور تمرکز دارد. در این حالت میتوان آنها را با استفاده از نمونههای ابری مجهز به GPU، بهویژه برای مجموعههای داده و مدلهای عظیمی که به وضوح فوقالعاده نیاز دارند، پیکربندی کرد.
بیشترین وظیفهی سرورهای هوش مصنوعی به عنوان پلتفرمهای بهرهوری اختصاصی برای انواع برنامههای کاربردی مبتنی بر هوش مصنوعی است.
ایستگاههای کاری هوش مصنوعی (AI workstations)
دانشمندان و مهندسان داده و محققان هوش مصنوعی اغلب از یک ایستگاه کاری هوش مصنوعی برای فرآیند ساخت و نگهداری برنامههای کاربردی هوش مصنوعی استفاده میکنند. این شامل آمادهسازی دادهها، طراحی مدل و آموزش مدل اولیه میشود. امکان ساخت نمونههای کامل از یک مدل از یک مجموعه داده بزرگ در ایستگاههای کاری براساس شتاب GPU امکانپذیر میشود که این فرآیند اغلب در چند ساعت تا یک یا دو روز انجام میگیرد.